A look at SGD from a physicist's perspective - Part 1
January 29, 2018
As a biophysics PhD student with a background in Applied Math and statistics, it’s hard not to be interested in Machine Learning. I’m currently working on drawing some ideas from non-equilibrium statistical physics and applying them to stochastic gradient descent. I decided it would be a good idea to organize my thoughts by writing a few blog posts. My plan is to chronologically cover one or more important articles in the field, in a synthetic and not-too-technical way. This post will provide a brief introduction to the analogies between statistical physics and machine learning, and list some fundamental references in this field. My next post (now up - see here) will focus on Radford Neal’s seminal ‘92 paper, Bayesian Learning via Stochastic Dynamics. The last post in this series (now up - see here) is the most practical; we’ll show how this approach to deep learning allows our algorithms to identify examples that they do not know how to classify. Our goal is to progressively make our way to modern approaches to stochastic gradient Langevin dynamics.
Thermodynamics in 3 minutes

Before we even get started, let’s cover a couple of concepts in thermodynamics:
Classical Thermodynamics / Statistical Mechanics
Imagine a pot of water sitting on your unlit gas stove. Why does the water sit nicely at the bottom of the pot? This is the result of the balance of two forces:
- the force resulting from the fact that water molecules like being next to each other; in other words, two molecules sitting next to each other will have lower energy than two molecules far apart.
- the force resulting from the statistical fact that the water molecules are more likely to be found in configurations that occur the most often. This is a simple combinatorial fact: there are many more ways for the molecules to be evenly distributed at the bottom of the pot than to have a higher density on the right side of the pot. There are a lot of molecules, so a ‘law of large numbers - like’ argument tells you that you’re very unlikely to see big departures from the uniform distribution.
The former, or energetic force is very familiar to us. The latter only holds for microscopic systems with randomness, and is the entropic force.
The ‘knob’ that adjusts the balance of forces between the energetic and entropic forces is the temperature. The higher the temperature, the higher the randomness, and the more the entropic force will dominate. This is exactly what happens when you turn on your stove and the water starts to boil: the molecules start being more random, and explore more configurations at the expense of the energetic force that makes them want to stick together. When the entire pot has turned to steam, the energetic force is zero, but the number of ways the molecules can be uniformly distributed around the room is exponentially larger than the number of ways they can be distributed in the pot.
At this point you may already ask - how is this even linked to machine learning? Let’s think of each particle \(i\) having a velocity \(p_i\) and a position \(q_i\) as being similar to each element \(w_i\) of some parameter vector \(\mathbf{w}\), like the coefficients in your linear regression, or the weights in your deep learning network. In the same way that the particles settle into an energetic minimum, the weights will settle into a configuration that minimizes a loss function. So, here we have our first bridge between thermodynamics and machine learning:
Energy in a given configuration (p, q) = Loss Function (w)
Ok, you say, but what I’m really interested in is not so much where we end up, as how to get there! Well, that’s one of the main problems in linking statistical mechanics to machine learning. Statistical mechanics was traditionally concerned with equilibrium states; that is, states in which the energy is minimum for the given entropy, or states in which the entropy is maximum for the given energy. In other words, states in which everything has settled down. To say interesting things about how we converge to the equilibrium state, we need to talk a little bit about…
Non-equilibrium statistical mechanics
Non-equilibrium statistical mechanics has a little bit of a rocky history. Many physicists will roll their eyes when you mention the subject. Why is that? Well, to start, almost everything in thermodynamics only has a meaning at equilibrium. For example, the concept of entropy doesn’t even exist out of equilibrium. To top it off, one of the most famous thermodynamicists and Nobel laureates, Ilya Prigogine came up with an out of equilibrium thermodynamic rule, the ‘minimum entropy production principle’, which turned out to be wrong…
That said, two major results in the nineties, the Crooks and Jarzynski fluctuation theorems, have since then legitimized more recent approaches to non-equilibrium thermodynamics, and have even seen many experimental verifications.
To get back to our water analogy, imagine this time that you have a bottle of water sitting on your table. We’ve already said that the equilibrium state of the water bottle, with the water uniformly distributed at the bottom of the water, is the result of classical thermodynamic forces. Now, shake the bottle and put it back down. The process taking place between the moment that the water bottle is put down and the moment that the water settles again into its equilibrium state is called relaxation. It’s a little bit past the scope of these posts, but it turns out that a major concept to quantify relaxation from a non-equilibrium state is Shannon Information, or, and perhaps more intuitively, the KL-Divergence between the equilibrium distribution and the non-equilibrium distribution.
Getting back to our ML algorithm, the transformation from our initial, randomly distributed weights to our final, minimum loss weights, is the exact mirror of this thermodynamic relaxation from an initial non-equilibrium state. This gives us our second analogy between machine learning and statistical physics:
Relaxation from an initial non-equilibrium state = Optimizing weights to learn from examples
But, what about entropy, you wonder. Well, there’s also some interesting connections there, but they’ll be easier to understand once we’ve covered next post’s article, Radford Neal’s Bayesian Learning via Stochastic Dynamics.
References
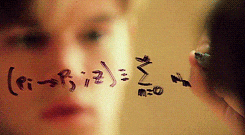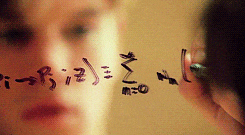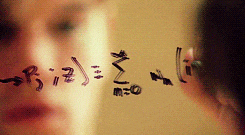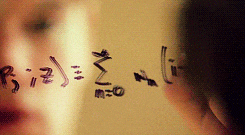
There’s a swath of litterature (starting in the early nineties) making connections between physics and machine learning. Some example articles from the nineties that I like are:
- Statistical mechanics of learning from examples, ‘92, Seung, Sompolinsky, and Tishby
- Statistical mechanics of learning a rule, ‘93, Watkin et al.
- Relationship between PAC, the Statistical Physics framework, the Bayesian framework, and the VC framework, ‘94, Wolpert
- Rigorous learning curve bounds from statistical mechanics, ‘96, Haussler et al.
There are even a couple of books that cover the subject more or less directly:
- Statistical Physics of Learning, ‘01, Engel and Van den Broeck
- Information theory, inference, and learning algorithms, ‘03, MacKay
- Information, Physics, and computation, ‘09, Mezard and Montanari
This line of research is still actively being conducted - here are some more recent interesting articles are:
- Bayesian learning via stochastic gradient Langevin dynamics, ‘11, Wellling and Teh
- Statistical Mechanics of High-Dimensional Inference, ‘16, Advani and Ganguli
Finally, some really good blog posts about these connections:
- Jaan Altosaar’s blog post covering the similarities between variational approaches in physics and variational inference
- Shakir Mohamed’s posts, for example this one covering the replica trick.
Please don’t hesitate to email me any feedback or questions! Thanks for reading, and please check out part 2 and part 3.
This work was supported by the ARO grant “Thermodynamics of Statistical Learning”, PI: H. Hess, ARO W911-NF-17-1-0107